Low-Latency Algorithm for Multi-messenger Astrophysics (LLAMA)’s Documentation¶
Docker Base |
Docker Env |
Docker Dev |
|---|---|---|



LLAMA is a reliable and flexible multi-messenger astrophysics framework and search pipeline. It identifies astrophysical signals by combining observations from multiple types of astrophysical messengers and can either be run in online mode as a self-contained low-latency pipeline or in offline mode for post-hoc analyses. It was first used during Advanced LIGO’s second observing run (O2) for the joint online LIGO/Virgo/IceCube Gravitational Wave/High-Energy Neutrino (GWHEN) search.
LLAMA’s search alorithm has been upgraded to run during LIGO’s third observing run (O3).
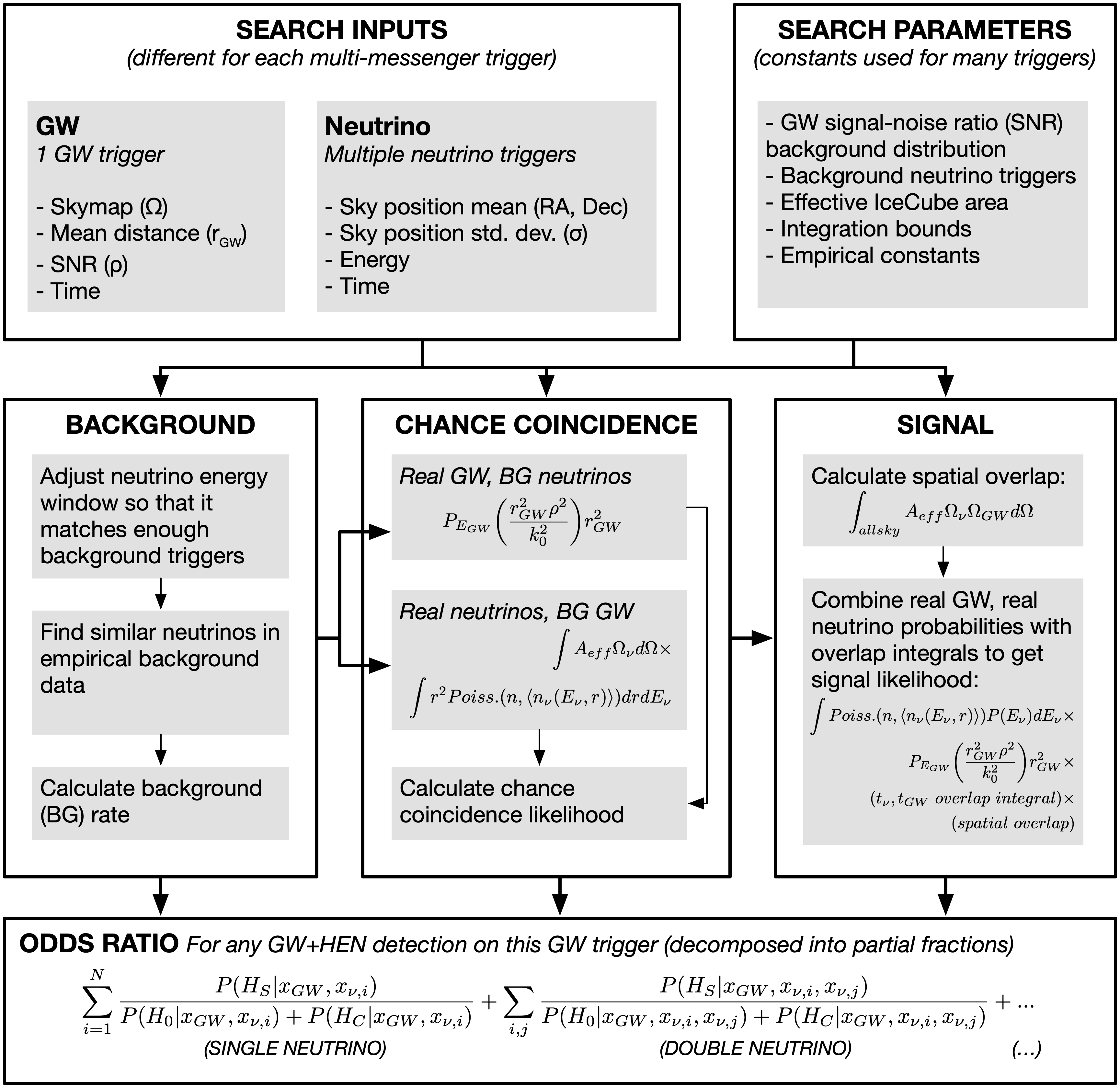
Flowchart describing the significance calculation used in the O3 version of the pipeline.¶
This full website can also be downloaded in
printer-friendly PDF format.
The LLAMA team thanks the many researchers working in LIGO/Virgo, IceCube, and other astrophysics projects that enable this pipeline to operate successfully. In particular, they thank Scott Barthelmy and Leo Singer of NASA for providing helpful code and advice for working with GCN.
The authors are grateful to the IceCube Collaboration for providing neutrino datasets and support for testing this algorithm. The Columbia Experimental Gravity group is grateful for the generous support of Columbia University in the City of New York and the National Science Foundation under grants PHY-1404462 and PHY-1708028. The authors are thankful for the generous support of the University of Florida and Columbia University in the City of New York.
Info for Reviewers
Quick Start Guide
Operators' Guide
- Introduction
- How Data is Organized
- Running the Pipeline Automatically
- Running the Pipeline Manually
- Sensitivity and Background Studies (O3B)
- Sensitivity and Background Studies (pre-O3B)
Developer's Guide
- Developer Installation
- Previous LLAMA Versions
- Developer Installation (Pre-O3)
- Configuration and Authentication
- External Authentication
- Turning on the Pipeline
- Developing for LLAMA
- Appendix
- Migrating to Conda
- Troubleshooting Installation
- Install IceCube Offline Software with Root
- Installing Ubuntu for Windows
- Logging in to a Remote Server Using SSH
- Getting LLAMA Software onto a Remote Server
- SSH with X11 Forwarding
- Using LLAMA
- Documenting LLAMA
- Troubleshooting LLAMA
- Setting Up the Review Server
- Ideas for the Future
- CVMFS
Bibliography
API Documentation
- llama.batch package
- llama.classes module
- llama.cli module
- llama.com package
- llama.detectors module
- llama.dev package
- llama.event package
- llama.filehandler package
- llama.files package
- llama.files.coinc_significance package
- llama.files.healpix package
- llama.files.i3 package
- llama.files.lvc_skymap package
- llama.files.skymap_info package
- llama.files.slack package
- llama.files.advok module
- llama.files.coinc_analyses module
- llama.files.coinc_o2 module
- llama.files.coinc_plots module
- llama.files.fermi_grb module
- llama.files.gcn_draft_o2 module
- llama.files.gracedb module
- llama.files.gwastro module
- llama.files.lvalert_advok module
- llama.files.lvalert_json module
- llama.files.lvc_gcn_xml module
- llama.files.lvc_skymap_mat module
- llama.files.lvc_skymap_txt module
- llama.files.matlab module
- llama.files.sms_receipts module
- llama.files.team_receipts module
- llama.files.timing_checks module
- llama.files.uw_summary module
- llama.files.ztf_trigger_list module
- llama.flags package
- llama.install package
- llama.intent module
- llama.io package
- llama.listen package
- llama.lock module
- llama.meta module
- llama.pipeline module
- llama.poll package
- llama.run package
- llama.serve package
- llama.test package
- llama.utils module
- llama.version module
- llama.versioning module
- llama.vetoes module
Code Reports
- Unit Tests
- Code Coverage
- Performance Profiling
- Combined Results
- Unit Tests
- Doctests
- llama.com
- llama.dev
- llama.filehandler
- llama.files
- llama.files.fermi_grb
- llama.files.healpix
- llama.files.i3
- llama.files.lvc_gcn_xml
- llama.files.lvc_skymap
- llama.files.matlab
- llama.utils
- Source Code Plots
Command Line Interface¶
llama batchllama comllama devllama eventllama filesllama flagsllama installllama listenllama pollllama runllama serve